

你以为 AI 产品靠的是算法?其实更重要的是业务认知与数据标签。本文通过数美内容审核 Agent 的打造过程,讲透 To B AI 产品的真实工作量公式:Coding < 标签数据 < 领域认知。

AIGC带来了内容的爆发式增长,由此很多公开产品(社交、电商、零售、教育、游戏、金融等领域)的内容审核工作遇到巨大挑战。传统人机协同模式下,日均 2000 万条内容需 60 人团队处理,年人力成本超 500 万元。
不仅内容审核的工作量大幅增加,AIGC巨大的组合创新能力(例如把男人的头像放在女性身体上避开以往的审核规则),对审核规则本身也带来了巨大挑战。
只有魔法才能打败魔法,只有基于LLM的AI审核才能应对AIGC带来的冲击——这,很有意思吧?
我最近调研的数美科技的内容审核Agent就是这样的产品。
我与创始人,以及市场负责人聊下来,第一感觉是——成功的toB AI产品都是相似的。
一、成功AI产品的共通之处
上周,我发短视频讲述目前看到的3种toB AI产品打造路径。其中基于行业认知、设计+生成(喂数据微调模型)的模式,我认为其成功路径是最清晰的。
我今年看了50个toB AI产品的详细路演,挑出来写成“AI产品体验官”系列的,目前只有3个。其它产品或产品打造路径,我还没看懂。而我写的这3篇,包括前面写过的北森AI面试官、慧算账记账Agent,有这样几个共通之处:
A、做AI产品必须基于公司既有优势。你做的不再是纯软件产品,而更像业务工作。AI技术和SaaS一样——纯技术门槛很低。没有凝结领域认知的AI产品,没有护城河。
B、AI产品的关键不是AI,而是积累的业务认知和数据。从工作量上反映出来就是:Coding工作量 < 数据打标签工作量 << 领域认知积累工作量
C、AI产品打造的思想基础是:还原论的“设计思维”+ 整体论“生成思维”
D、寻找不需要做最终决策的场景(并设计容错机制)
从表象上看,这条路径最显著的特点就是:需要大量喂专业标签数据,而不是靠冗长的prompt提示语就能产生足够好的效果。
(此外,也需要根据领域深度认知产品架构设计。但这一条就不够“显著”了。)
二、数美也吻合这4个共通特点
数美成立于2015年,也是成立有十年的创业公司了。
我问创始人唐会军兄:数美的护城河在哪里?
他告诉我,是对内容“风险类型”的深入研究。数美已经积累了几千个风险类型,例如:暴力、炫富、躺平……等。这源自十年来,产品经理们对真实世界内容风险的发现和定义。(在数美,产品经理各自负责不同方向的内容风险研究。)
笔者理解数美还有第二个护城河,就是数据飞轮。数美目前每天处理数十亿张图片和文本,十年来积累了万亿次过滤。数据飞轮效应令新玩家难以入场,唯一要忌惮的是同样拥有海量数据的大厂。
“内容审核Agent”的产品结构也是设计+生成的逻辑:先划分了几千个风险类型,然后为每个风险类型喂200个到5000个不等的标签样本数据对大模型进行微调,合计千万级投喂数据量。
从工作量上来看,这个Agent产品的开发过程也符合这个公式:
Coding工作量 < 数据打标签工作量 << 领域认知积累工作量
此外,从场景上看,大部分情况下都不再需要“人工审核”最后把关——内容审核Agent可以识别和拦截有风险的内容;对于小部分复杂高疑的内容,人工会兜底——复审完成交叉验证。
三、数美AI产品的独特之处
但是,内容审核Agent面对的业务场景与其它AI产品不同,因此也有很多独特之处。
第一,尽量兼容现有流程
与上次我谈的慧算账“记账Agent”颠覆软件服务范式不同,数美服务大企业和政府部门,考虑的是“最大限度兼容现有流程”。
例如,Agent插在“机审服务”与“人审复核”之间。是机审服务的补充,但不影响原有人审复核的工作流程。
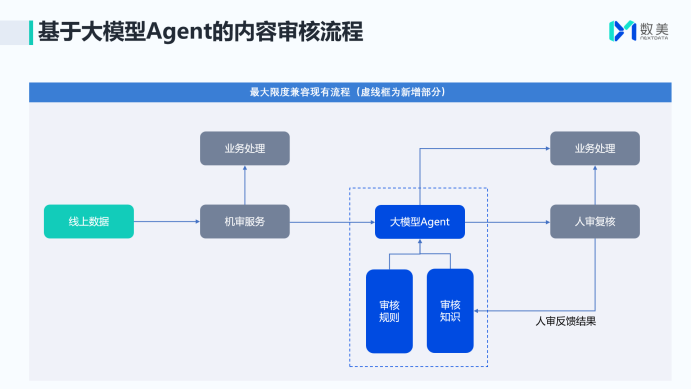
例如,机审过滤后仍有3%存疑内容,Agent进行二次筛查后仅保0.3%-1.5% 高疑案例进入人工环节。
同时,利用人工反馈的判例,为Agent的审核知识库补充内容。
第二,“对抗”需要更多技术突破
内容审核需要平衡其服务的平台产品的业务发展需求与合规需求。说白了,既不能让违规内容漏网,也不能误杀合规内容影响用户体验。
与其它业务系统不同,该Agent需要与大量内容生产AI产品进行对抗。
图文结合的多模态识别就是其中一个例子。一个图文作品,文字没毛病、图片单独看也没毛病,但文配图会产生全新的意思,也许就违规了。
以往的机器审核无法判断,但拥有了LLM(大语言模型)技术的内容审核Agent就具备了这个能力。
第三,用AI做数据创新
再举个例子,很多“擦边”内容的样例非常少。为了让AI能够识别这类风险内容,数美的工程师会用AI生成一批“类似内容”,然后喂给大模型进行训练。
可以看到,很多成功AI产品的打造过程就是这样:主要工作量往往不在编程coding上。
总结
目前,数美的大模型审核Agent产品已达到98%-99%的准确率和99.5%的查全率(也称为召回率,即找出所有正样本的比率)。
该AI产品达到的效果是:
* 进一步提升机器审核对高风险内容的识别准确率和召回率
* 人审成本降低了70%-90%
* 审核员专注标注而非全流程处理,单人日效从 1 万条提升至 3-5 万条;
我个人给该产品的打分很高。特别是在体验价值方面,因为场景可控(失误可补救)、交互成本低(不改变原有流程),所以三个分数分别得到8、8、7。

而在商业潜力方面,应用场景很多(而且由于内容审核是全球高一致性需求,出海机会也很不错),但笔者估计面对大客户销售成本不低、且海外PLG模式还在拓展阶段,因此得分中等。
(我不是安全方面的专家,仅从SaaS+AI产品商业化的角度探讨,欢迎指正。)
前两天有读者在我的视频号下问到:“中国的Saas还能看到曙光吗?”
我回答说:必然能。3年来,AI连大部分C端应用场景都搞不定,在C端更适合辅助个人提升效率;在B端只赋能SaaS而非颠覆。
AI的智能还远远不能达到AGI(通用人工智能)的程度,Gartner预测它离成熟还需要超过10年。在真正实现AGI之前,toB应用只能维持今天的局面:SaaS为主(软件工程设计)+ AI赋能具体场景(LLM生成局部智能)。
而在AGI实现之后,社会经济形态都会彻底改变,那也无关SaaS了……
本文由人人都是产品经理作者【吴昊@SaaS】,微信公众号:【SaaS白夜行】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。













