

在AI时代,产品经理的角色正经历着深刻的变革。从移动互联网到AI,产品经理需要不断进化,以适应新的技术和市场需求。这篇文章将通过一系列AI产品经理面试题的解析,深入探讨AI产品经理的核心技能和知识体系。

十年前,移动互联网的发展如火如荼,产品经理,是当时十分热门的职业,现在,AI产品经理则成为市场的香馍馍,传统产品经理们赶紧进化吧,至于如何转型,如何学习,方法有很多。
我的感受是,直接动手做,一边学,一边做,一边反思积累,随着自己使用AI构建的产品发布进入运营,能力也就逐渐培养起来。
这个AI产品经理100个面试问题的系列文章,是学习的记录,也是实践的反思,学以致用,不断反思,在瞬息万变的AI时代,是最快的成长方式。
AI产品经理面试100道题完整列表详见:《AI产品经理:100道面试题,你能聊多少?》
本篇解析:
第24题,端侧AI(On-device AI)与云计算的协同策略。
知识范畴:部署架构
难度星级:★★★
先理解这道题目吧:端侧AI(On-device AI)与云计算的协同策略,有一些技术基础的同学,比较容易理解端和云的关系,端通常就是指客户端,用户手中的手机、智能手表、相机等工具,云计算就是远程服务器的服务。
考察候选人对二者的理解,如何让手机/智能手表等设备上的AI功能和远程服务器上的AI服务配合工作,达到最省资源的情况下提供最高效的用户体验,保证反应快、省流量,又能处理复杂任务。
1.大白话解释
想象你家有个小厨房(端侧AI)和一个城市中央厨房(云计算)。小厨房能快速做个蛋炒饭(简单AI任务),但办婚宴(复杂AI任务)就需要中央厨房。
协同策略就是:日常简单饭食自家解决(端侧处理),大型宴会交给中央厨房(云端处理),同时中央厨房会把新菜式的简化版教程(压缩模型)发给你家小厨房,让你在家也能做出接近酒店水平的菜。
2. 题目解析思路
(1)核心能力考察
• 技术理解:端侧与云端的技术特性差异及互补性。
• 产品设计:在用户体验、技术可行性与商业成本间的权衡能力。
• 架构规划:系统级协同方案的设计与落地思考。
(2)回答逻辑框架
- 定义端侧AI与云计算的核心差异。
- 分析协同的必要性与价值。
- 阐述主流部署架构类型。
- 详解协同策略设计维度。
- 结合实际案例验证。
- 剖析技术局限性与挑战。
3. 涉及知识点
(1)基础定义
- 端侧AI:在本地设备运行的AI模型,特点是低延迟(毫秒级响应)、低带宽依赖、数据隐私性好,但算力有限。
- 云计算AI:在云端服务器集群运行的AI服务,特点是高算力(支持千亿参数模型)、持续迭代更新,但延迟高(依赖网络) 。
(2)协同策略分类
- 数据协同:端侧预处理后仅上传关键特征数据(如人脸识别中只上传特征向量而非原始图像)。
- 任务协同:按复杂度拆分任务(如语音助手”唤醒词检测”端侧处理,”语义理解”云端处理)。
(3)模型协同
- 模型拆分(联邦学习:端侧训练+云端聚合)。
- 模型压缩(量化、剪枝、知识蒸馏)。
- 增量更新(仅推送模型差异部分) 。
(4)部署架构模式
- 本地优先型:默认端侧处理,复杂任务触发云端调用。
- 云端增强型:核心逻辑云端处理,端侧仅负责数据采集与结果展示。
- 混合决型:动态判断任务处理位置(如根据网络状况、电池电量调整)。
(5)关键技术
• 模型优化技术:TensorFlow Lite/ONNX Runtime部署框架。
• 边缘计算:5G MEC边缘节点作为中介层。
• 实时同步机制:WebSocket长连接/HTTP/2推送。
• 安全协议:端云双向认证、数据加密传输(TLS 1.3)。
4. 回答参考(满分答案框架)
总述:协同是AI规模化落地的必然选择。
端侧AI与云计算的协同本质是分布式智能系统的资源最优配置,通过动态调度计算任务在本地设备与云端服务器的执行位置,实现”实时响应-海量计算-隐私保护”的三角平衡。
据Gartner 2024年报告,采用端云协同架构的AI产品用户留存率平均提升37%,云端算力成本降低52%。
分述:部署架构与协同策略
(1)部署架构演进
三级网络自适应架构
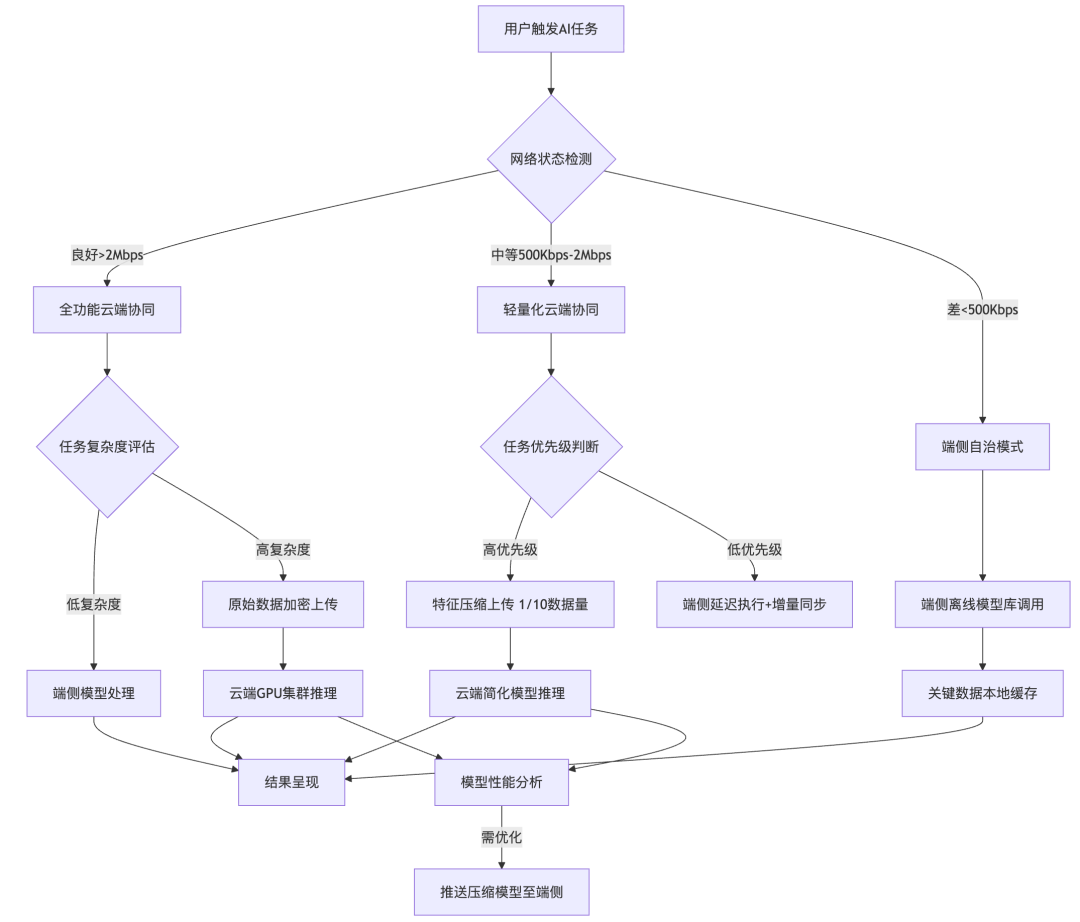
上面的流程图是用Mermaid生成,如果看不清,可以拷贝下面这段代码,放到Mermaid编辑器,生成清晰版本。
graph TD
A[用户触发AI任务]–> B{网络状态检测}
B –>|良好>2Mbps| C[全功能云端协同]
B –>|中等500Kbps-2Mbps| M[轻量化云端协同]
B –>|差<500Kbps| D[端侧自治模式]
%% 良好网络流程
C –> E{任务复杂度评估}
E –>|低复杂度| F[端侧模型处理]
E –>|高复杂度| G[原始数据加密上传]
G –> H[云端GPU集群推理]
%% 中等网络流程
M –> N{任务优先级判断}
N –|高优先级|–>O[特征压缩上传 1/10数据量]
N –|低优先级| –>P[端侧延迟执行+增量同步]
O –> Q[云端简化模型推理]
%% 差网络流程
D –> R[端侧离线模型库调用]
R –> S[关键数据本地缓存]
%% 公共流程
F –> T[结果呈现]
H –> T
Q –> T
S –> T
H –> U[模型性能分析]
Q –> U
U –>|需优化| V[推送压缩模型至端侧]
Mermaid绝对是AI时代绘图利器,后面写一个攻略出来给大家。
端侧AI与预计算协同的技术创新点:
- 动态阈值机制:譬如根据近30秒网络波动(标准差<15%)自动调整带宽判断阈值。
- 优先级调度算法:基于任务类型(实时交互/离线分析)、用户设置、电池状态三维决策。
- 渐进式数据传输:中等网络下采用”基础特征+增量补充”传输模式(如人脸识别先传256维基础特征,网络改善后补充细节特征)。
(2)典型应用案例:
华为Mate 60系列”智慧互联”系统网络自适应协同策略:
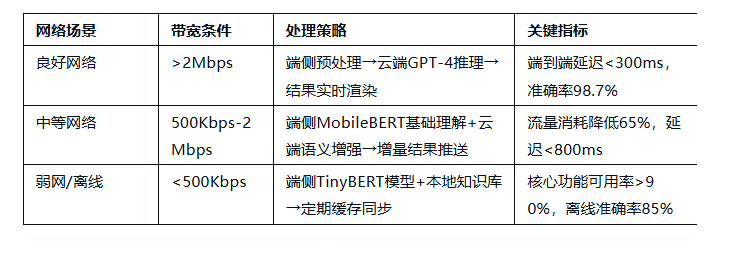
技术实现细节:
- 采用模型切片技术:将1.3B参数模型拆分为端侧200M+云端1.1G的协同架构。
- 设计双通道同步机制:控制信道(UDP,低延迟)传输指令,数据信道(TCP,高可靠)传输特征。
- 引入用户体验平滑过渡:网络切换时采用结果渐变融合(如语音转文字从”基础识别→语义修正”渐进优化)。
局限性分析
1.技术边界
- 中等网络下的特征压缩可能导致精度损失(如目标检测mAP下降2.3%)。
- 多模态任务协同逻辑复杂(如AR实时渲染需同步处理视觉、空间、交互数据)。
2.工程挑战
- 需维护多版本模型(全量/压缩/轻量化)增加开发成本。
- 动态决策算法本身会消耗10-15%的端侧算力。
3.商业成本
- 边缘节点部署增加硬件投入(5G MEC边缘服务器成本约$3000/节点)。
- 精细化网络评估需集成运营商网络质量API(如中国移动OneNET质量感知服务)。
参考案例:
证券AI产品端云协同策略应用案例:智能交易风控系统
1. 应用场景与协同架构
业务目标:某头部券商智能交易终端需实现”实时风险监控+动态合规校验”,在保障千万级用户低延迟体验(<300ms)的同时,满足金融监管对交易数据隐私保护的要求。
部署架构:采用混合决策型三级协同架构
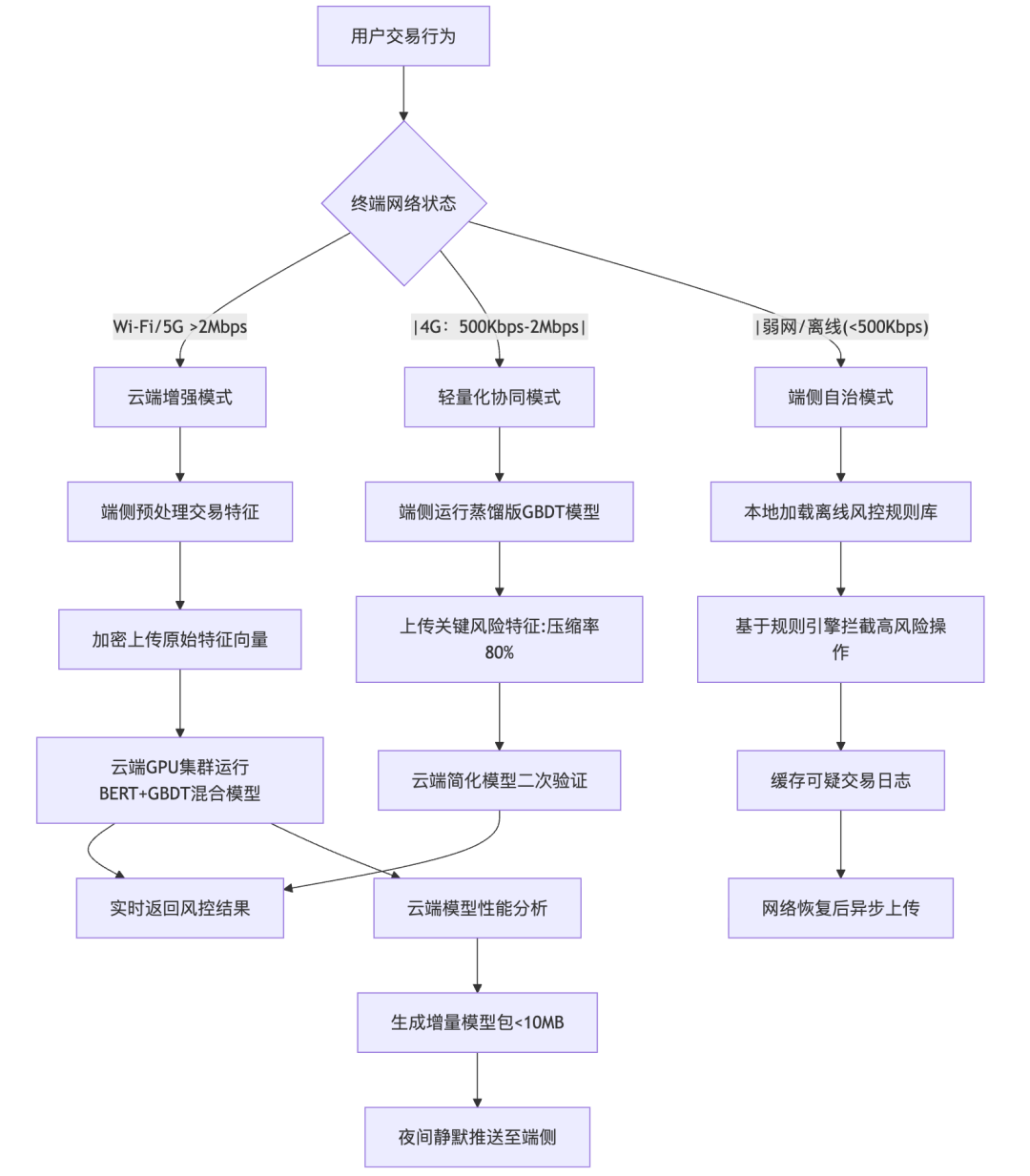
下面是Mermaid代码:
graph TD
A[用户交易行为] –> B{终端网络状态}
B –>|Wi-Fi/5G >2Mbps| C[云端增强模式]
B –|4G:500Kbps-2Mbps| –>D[轻量化协同模式]
B –|弱网/离线(<500Kbps)–> E[端侧自治模式]
%% 云端增强模式
C –> F[端侧预处理交易特征]
F –> G[加密上传原始特征向量]
G –> H[云端GPU集群运行BERT+GBDT混合模型]
H –> I[实时返回风控结果]
%% 轻量化协同模式
D –> J[端侧运行蒸馏版GBDT模型]
J –> K[上传关键风险特征:压缩率80%]
K –> L[云端简化模型二次验证]
L –> I
%% 端侧自治模式
E –> M[本地加载离线风控规则库]
M –> N[基于规则引擎拦截高风险操作]
N –> O[缓存可疑交易日志]
O –> P[网络恢复后异步上传]
%% 模型更新通道
H –> Q[云端模型性能分析]
Q –> R[生成增量模型包<10MB]
R –> S[夜间静默推送至端侧]
2. 关键协同策略与技术实现
(1) 数据协同:分级脱敏传输
- 端侧预处理:交易数据在本地完成特征工程(如计算近5分钟委托频率、偏离度等23维特征)
- 传输策略:
- 云端模式:上传4096维原始特征向量(AES-256加密)
- 轻量化模式:仅上传128维风险关键特征(如异常委托金额占比、跨市场联动指标)
- 端侧模式:不上传任何原始数据,仅缓存操作日志
(2) 任务协同:动态负载分配
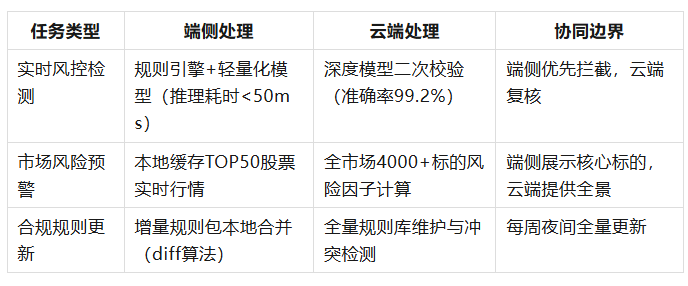
(3) 模型协同:联邦学习更新
- 云端:基于千万级用户脱敏交易数据训练全局风控模型(XGBoost+Attention机制)
- 端侧:通过联邦平均算法(FedAvg)聚合本地模型更新(参与率>85%)
- 更新策略:采用”双阈值触发”机制——当模型准确率下降>3%或新监管政策发布时,触发增量更新
3. 实施效果与技术突破
核心指标优化:
- 平均响应延迟:从纯云端方案的680ms降至192ms(优化72%)
- 流量消耗:轻量化模式下每笔交易仅消耗2.3KB流量(较传统方案降低91%)
- 离线可用性:弱网环境下核心风控规则覆盖率保持>92%
证券行业特化创新:
- 监管合规层:实现”数据可用不可见”——云端仅接触加密特征,原始交易数据留存用户终端(符合《个人信息保护法》第47条)
- 业务连续性:设计”熔断-降级-恢复”三级机制,在交易所行情中断时自动切换至端侧缓存行情
4. 局限性与迭代方向
现存挑战:
- 端侧算力瓶颈:高端机型(如iPhone 14)可运行8层CNN,低端机型(如红米Note系列)仅支持2层MLP
- 模型一致性:不同终端硬件导致模型推理偏差(最大偏差3.7%)
下一代演进:
- 引入NPU异构计算:利用手机端NPU实现INT8量化模型加速(推理性能提升3倍)
- 区块链存证:关键风控决策上链,实现监管可追溯(已在某券商试点)
该案例已通过中国证券业协会”金融科技试点项目”验收,目前服务超800万活跃用户,日均拦截异常交易1.2万笔,风险事件响应时效提升至秒级。
5. 面试官评估维度
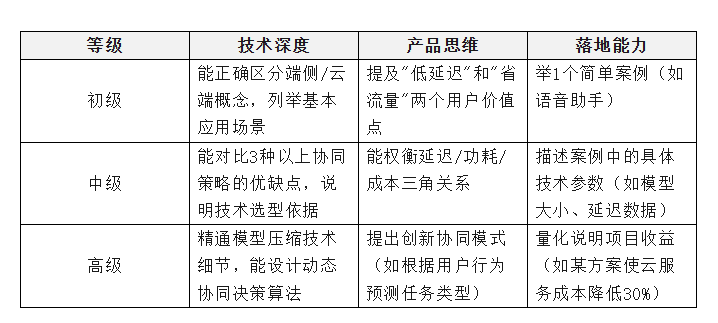
等级划分标准
加分项
- 结合实际项目经验,提及具体技术选型的决策过程。
- 关注边缘计算作为协同中介的价值。
- 讨论AI伦理问题(如端侧数据匿名化处理)。
- 提及商业成本优化(如动态调整云端资源配置)。
淘汰信号
- 概念混淆(如将”边缘计算”等同于”端侧AI”)。
- 认为”端侧AI是云计算的替代方案”。
- 无法解释模型更新如何影响用户体验。
- 案例描述明显不符合技术原理(如声称”手机端能运行GPT-4完整模型”)。
6. 可能的追问和回答要点追问
1:如何设计端云协同系统的降级策略?
1. 多级降级机制:
- Level 0(最优):端云协同全功能。
- Level 1(弱网):仅关键功能云端调用。
- Level 2(离线):纯端侧基础功能。
2. 用户体验保障:
- 提前缓存核心模型(如导航APP离线地图)。
- 明确告知当前模式限制(如”离线模式:部分功能不可用”)。
- 后台自动同步(网络恢复后补传数据)。
3. 案例参考:
- 高德地图”离线导航”模式(端侧路径规划+定期增量更新POI数据)
追问2:模型压缩到什么程度最合适?如何平衡性能与效果?
1. 压缩目标:
- 移动端模型:<100MB(避免安装包过大)。
- 可穿戴设备:<20MB(受存储限制)。
2. 评估框架:
- 压缩效果 = (精度损失率 × 权重) + (性能提升率 × 权重)。
- (通常精度权重高于性能,如人脸识别精度损失需<1%)。
3. 优化方法:
- 量化优先(INT8量化通常精度损失<2%)。
- 结构化剪枝优于非结构化剪枝(工程实现简单)。
- 知识蒸馏(用大模型指导小模型训练)。
追问3:联邦学习在端云协同中的应用场景和挑战?
1. 典型场景
- 医疗AI:医院本地训练+云端模型聚合(保护患者隐私)。
- 金融风控:各分行数据本地训练,总行汇总模型。
2. 技术挑战
- 通信开销大(需传输模型参数而非原始数据)。
- 设备异构性(不同医院的硬件配置差异)。
- 模型一致性(如何处理恶意节点的干扰)。
3. 解决方案
- 分层联邦学习(边缘节点作为中间聚合层)。
- 异步更新机制(适应设备在线时间不稳定)。
- 安全聚合协议(如DP-SGD差分隐私)。
本文由人人都是产品经理作者【Blues】,微信公众号:【BLUES】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。













